Data Science projecten en ervaring
Onze data scientists hebben uiteenlopende projectervaring. Hier een aantal voorbeelden van projecten waar zij waardevolle ervaring hebben opgedaan.
Voorspellen van administratieve werklast
We hebben voor een grote hypotheek- en kredietverlener een end-to-end oplossing ontwikkeld om de werkvoorraad van een afdeling van < 50 FTE te voorspellen. Dit lukte tot op wel 95% nauwkeurigheid, en voorspelt tot 6 weken van te voren het aantal taken per week. Dit heeft de werkefficiëntie aanzienlijk verhoogd.
Voorspellingsmodel wanbetaling van leningen
In het kader van innovatie en ontwikkeling hebben we een model gebouwd dat voorspelt of klanten van financiële dienstverleners wel of niet hun lening kunnen afbetalen. Dit model is, op basis van een historische dataset, gemaakt met gebruik van machine learning-componenten van Microsoft Azure. Het nauwkeurigheidspercentage van dit model is 97%.
Predictive maintenance
In dit project is een voorspellend ensemble-model gebouwd voor een grote Nederlandse zaadveredelaar. Dit model voorspelt de delta in het peil van vloeibare kunstmesttanks voor de komende tien dagen, op basis van Internet of Things (IoT) data over peilmetingen en verrijkt met open data van het KNMI. Met deze voorspellingen kon route-optimalisatie gedaan worden door meerdere tanks in één rit bij te vullen voordat ze onder het kritieke niveau zouden komen, ter kostenbesparing.
Anomaly detection op server metrics
Voor een grote bank hebben we een ensemble-model gebouwd om onregelmatigheden te detecteren op servermeetwaarden, en hebben hiervoor een Spark/Hadoop cluster ingericht waarop het model draait. Hierdoor is het inzicht op cloudgebruik en -kosten voor deze klant vergroot, en zijn er mogelijkheden om het op- en afschalen van hun cloud te automatiseren.
Inzicht in database-monitoring
In dit project is de monitoring van een Cassandra big data database effectiever gemaakt d.m.v. een effectievere selectie van metrics. Hierbij is de data verkend en inzichtelijk gemaakt met visualisaties in Jupyter notebooks. Vervolgens is een eerste, overdraagbaar product gemaakt op basis van een Python Flask API ingebed in een docker container. Door middel van deze API kunnen de databasebeheerders op ieder willekeurig moment een analyse test op de data laten uitvoeren om zo te zien welke metrics zeer waarschijnlijk de veroorzakers zijn van lange responstijden.
Laat data science voor jou werken
Wil jij d.m.v. data science, alle waardevolle informatie uit jouw data halen om daarmee jouw businessdoelen te realiseren? Laat onze data scientists voor jou aan de slag gaan! Neem contact op ons via sales@kvl.nl.
Hoe ziet het vervolg eruit?
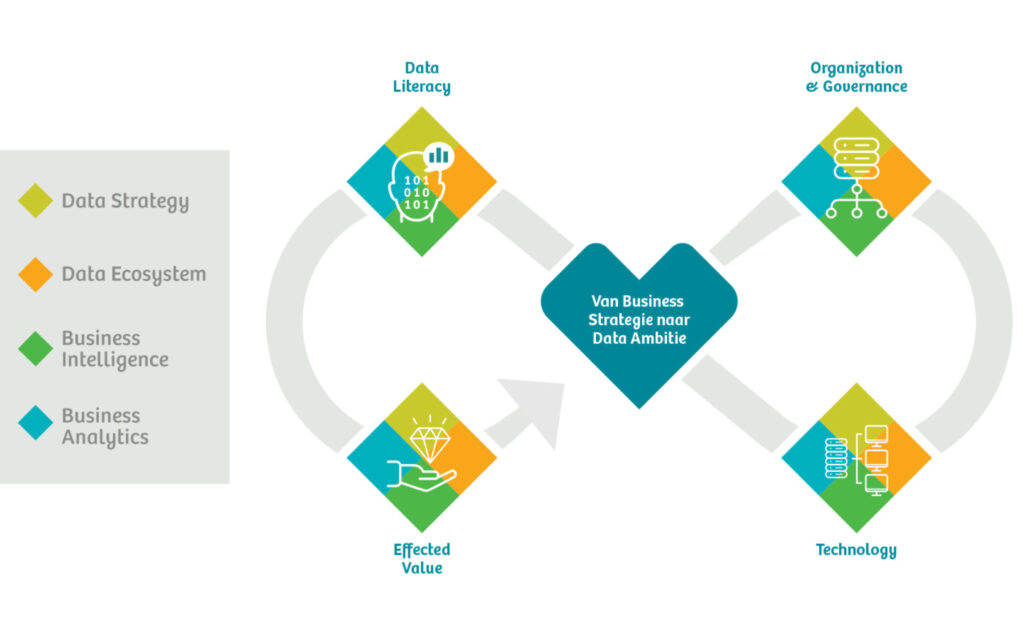
Een eerstvolgende stap kan bijvoorbeeld het uitvoeren van een diepgaander Data Value Assessment zijn. Hiermee maken wij aan de hand van een Fit-Gap analyse inzichtelijk welke Data & Analytics domeinen, en welke drivers daarbinnen, (extra) aandacht behoeven. Op basis van de geconstateerde gaps maken wij vervolgens een concrete Data Roadmap waarin de uitkomsten uit het Data Value Assessment omgezet worden naar praktische stappen voor de korte en langere termijn.
Kan ik hiermee zelfstandig verder?
Het eindresultaat is tastbaar en is de eerste stap in het ontwikkelen van een winnende datastrategie en het bijbehorende implementatieplan. Jouw organisatie kan de eindresultaten omarmen en een vervolg geven aan de realisatie van de geformuleerde data-ambitie.
Jouw route naar succes met data
Heb je interesse in onze Canvassessie? Neem dan contact op met Martin Vermeule: mvermeule@kvl.nl of bel 06 82 589 819.
Contactformulier
"*" indicates required fields

Hoi, ik ben Bas.
Wij maken organisaties datagedreven. Maak vrijblijvend een afspraak, we helpen je graag op weg met Data & Analytics.
Neem contact op